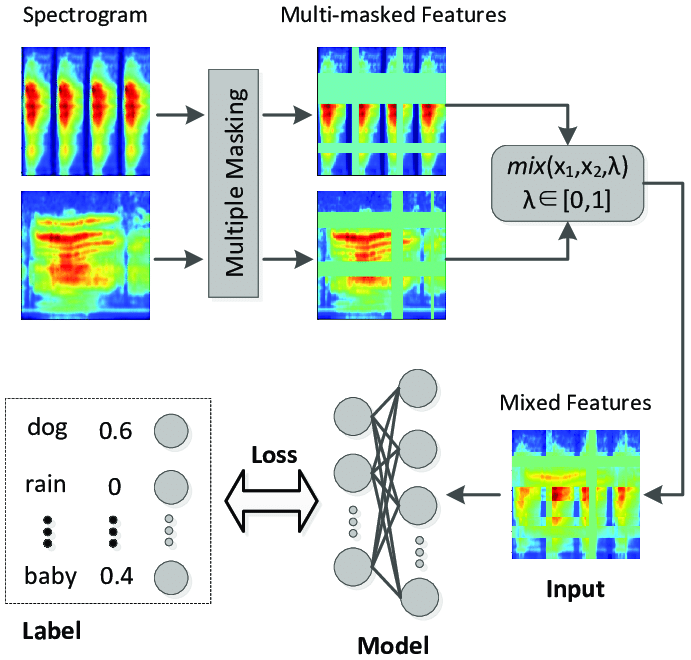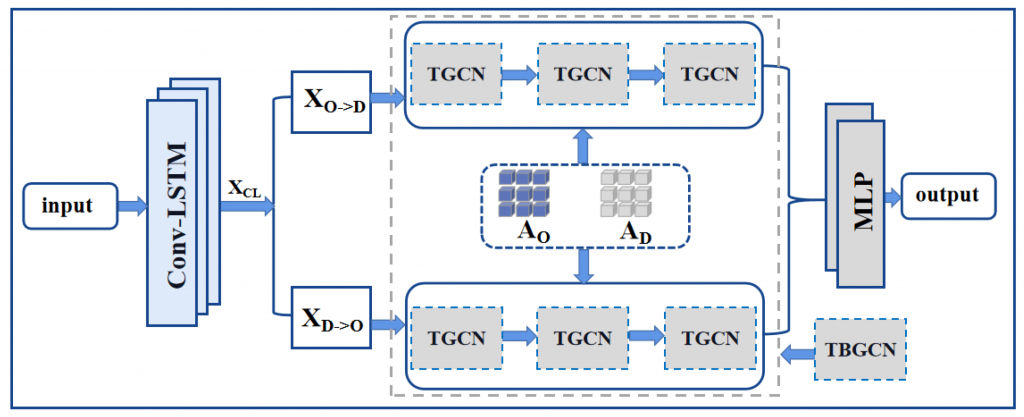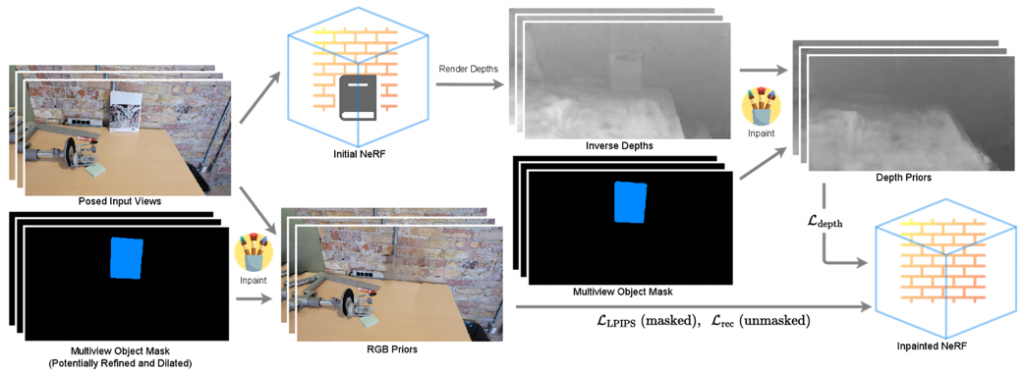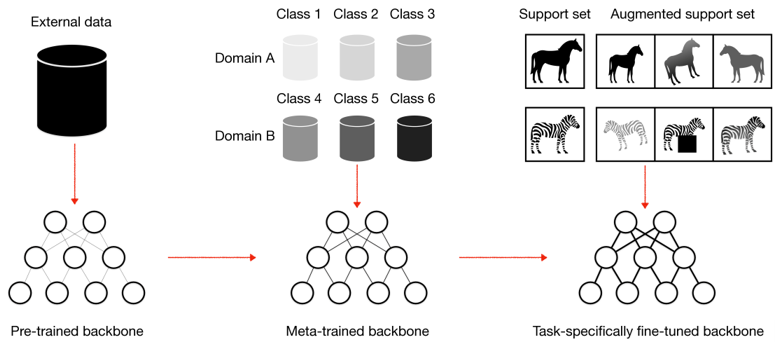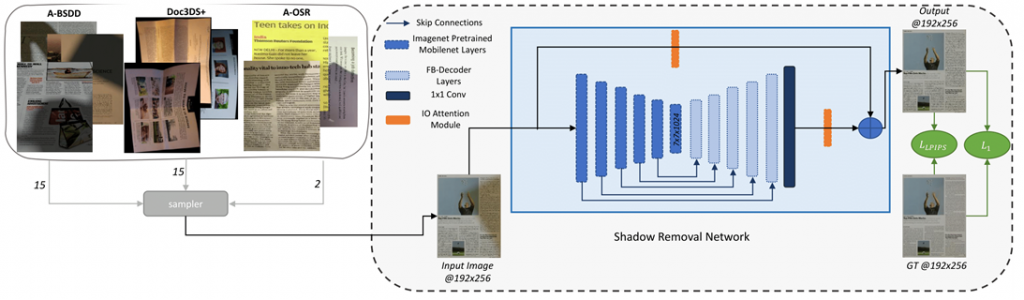
LP-IOANet: Illuminating the Future of Document Enhancement with Efficient High-Resolution Shadow Removal
Introduction In the realm of document processing and image enhancement, the significance of clear, legible, and high-resolution documents cannot be overstated. However, the presence of shadows in scanned or photographed documents can often pose a significant challenge. Enter LP-IOANet – an innovative solution designed for Efficient High-Resolution Document Shadow Removal. In this article, we will …